

Reading Ambitiously 10-3-25
Nvidia at $4.5T+, SiriGPT, ThinkingMachines, OAI & Nvidia's 10GW, Microsoft Excel w/ AI, Meta Smart Glasses, D/E ratios, Sora 2, Picks & Shovels, LLMs cite Reddit
Enjoy this week’s Big Idea read by me:
Please note that, as of this writing, Nvidia’s market capitalization is $4.59 trillion. The podcast previously stated $4.44 trillion.

The big idea: Nvidia… chip manufacturer or AI factory builder?

My relationship with Nvidia dates back to my first job at Milwaukee PC, a local competitor to Gateway and Dell. Employees could buy hardware at a discount to build their own machines.
When building a computer, what’s the first thing you buy? It’s likely the CPU. Back then, the market was dominated by Intel and its “core” series of chips. It is the brain of the computer. But the flagship part of every system I ever built, and my most prized possession, was always the graphics card. It was expensive, often scarce, and made by Nvidia.
That year, Nvidia’s market capitalization was $19 billion, up from $4 billion during the GFC. As of this writing, Nvidia commands a market cap of $4.59 trillion, the largest in the world.
That is more than double Canada’s GDP. It is more than the combined value of McDonald’s, Coca-Cola, Starbucks, and Chipotle by a factor of six.
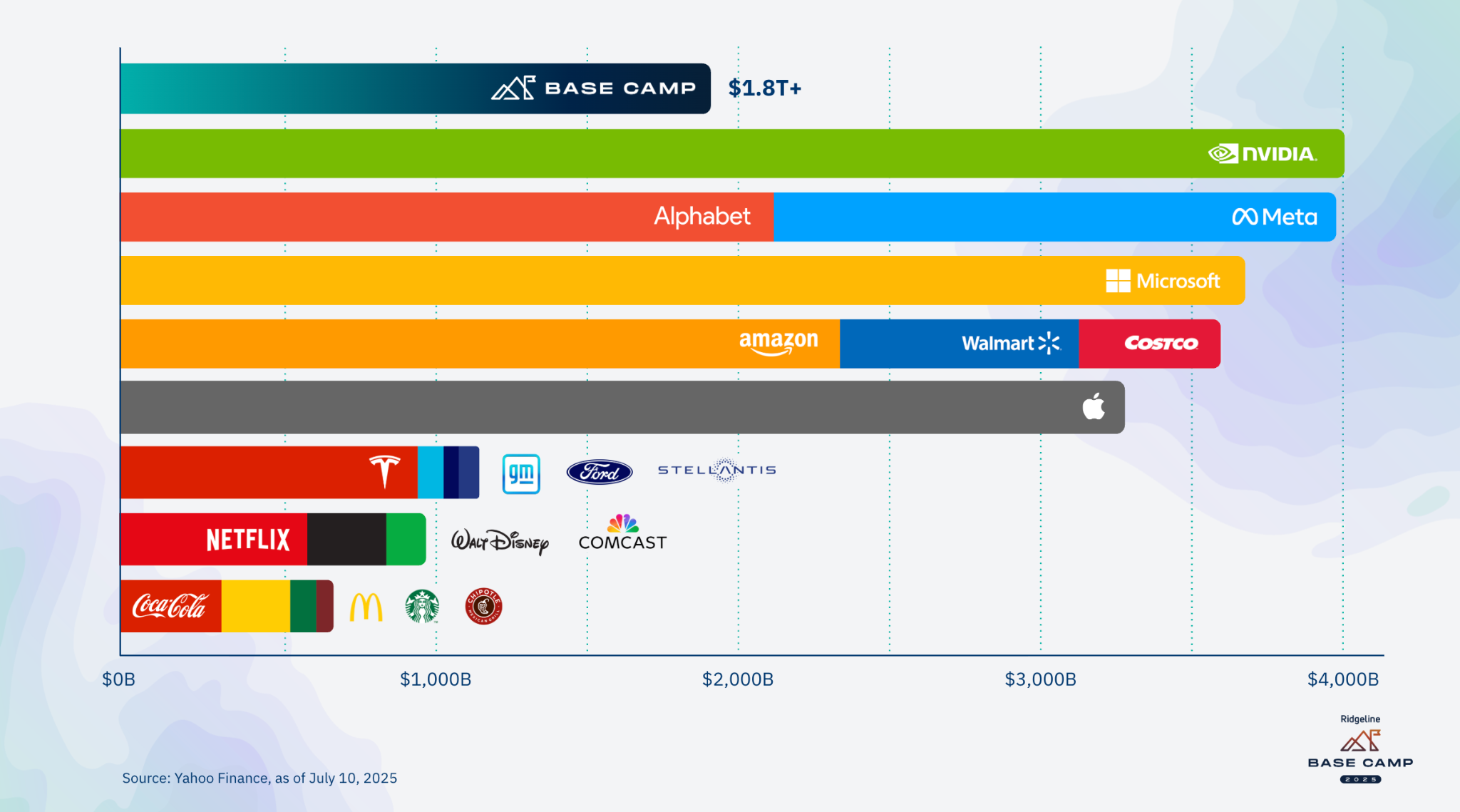
The scale of AI adoption explains why:
ChatGPT reached 100 million users in just two months (Twitter took five years, and Netflix, ten). ChatGPT is now reportedly above 700 million users.
The Ford Model T took 2,500 days to reach 1 million customers. ChatGPT achieved this milestone in just five days.
Google is now processing 980 trillion AI tokens — 100× more than just two years ago.
The question for ambitious readers isn’t whether AI is big, or that Nvidia is playing a central role, it clearly is, and they clearly are.
The question is: is Nvidia still a chip company that sold me that graphics card, or are they building AI factories capable of augmenting the intelligence of the world’s knowledge workers?
The Market for AI Infrastructure
When Jensen Huang, Nvidia’s Founder, talks about Nvidia today, he doesn’t describe a chip company. He describes an AI infrastructure company.
His mental model begins with the economy itself. Knowledge work accounts for 55–65% of the global GDP, which is roughly $50 trillion. If AI augments even a fraction of that, the TAM is enormous. Huang’s back-of-the-envelope math: add $10T of output, assume ~50% gross margins, and you get $5T per year that must be supported by AI infrastructure.
Those machines are what he calls AI factories:
“Where motors replaced physical labor, AI factories will augment human intelligence… In the past the software was written once. Now the software is in fact writing all the time — it’s thinking. And in order for the AI to think, it needs a factory.” — Jensen Huang
Unlike first-generation LLMs that returned an answer in a single shot, today’s “thinking models” use inference computing to reason step by step. They may break down a problem, check their own work, utilize external tools, or generate multiple drafts before making a decision. Each of those steps consumes tokens, and tokens consume power. That’s why inference has become the primary workload of AI factories.
This is also why hyperscalers are investing heavily in infrastructure on a scale that rivals national projects. This past year, Microsoft, Google, Amazon, and Meta alone invested $364B in AI infrastructure.

Jon Gray of Blackstone recently noted that this spending exceeds the combined budgets of national infrastructure programs, including NASA, the Department of Energy, and the Department of State.
The Scaling Laws
If AI factories are the supply side, scaling laws are the demand engine. They describe how AI performance improves as more compute is added.
For years, the objective has been to scale up model size and dataset size during pre-training, resulting in improved AI models. This is why it was rumored that GPT-4 cost OpenAI over $100M to train.
At CES 2025, Huang claimed that there are now three AI scaling laws:
Pre-training — the traditional path: bigger models trained on more data. (OAI’s $100m training run)
Post-training — reinforcement learning and fine-tuning, where the model practices until it masters a skill. (what ScaleAI helps with, recently acquired by Zuck/Meta)
Inference or Test-Time Compute — the newest and most underestimated: compute spent at test time, where the model “thinks” before producing an answer.
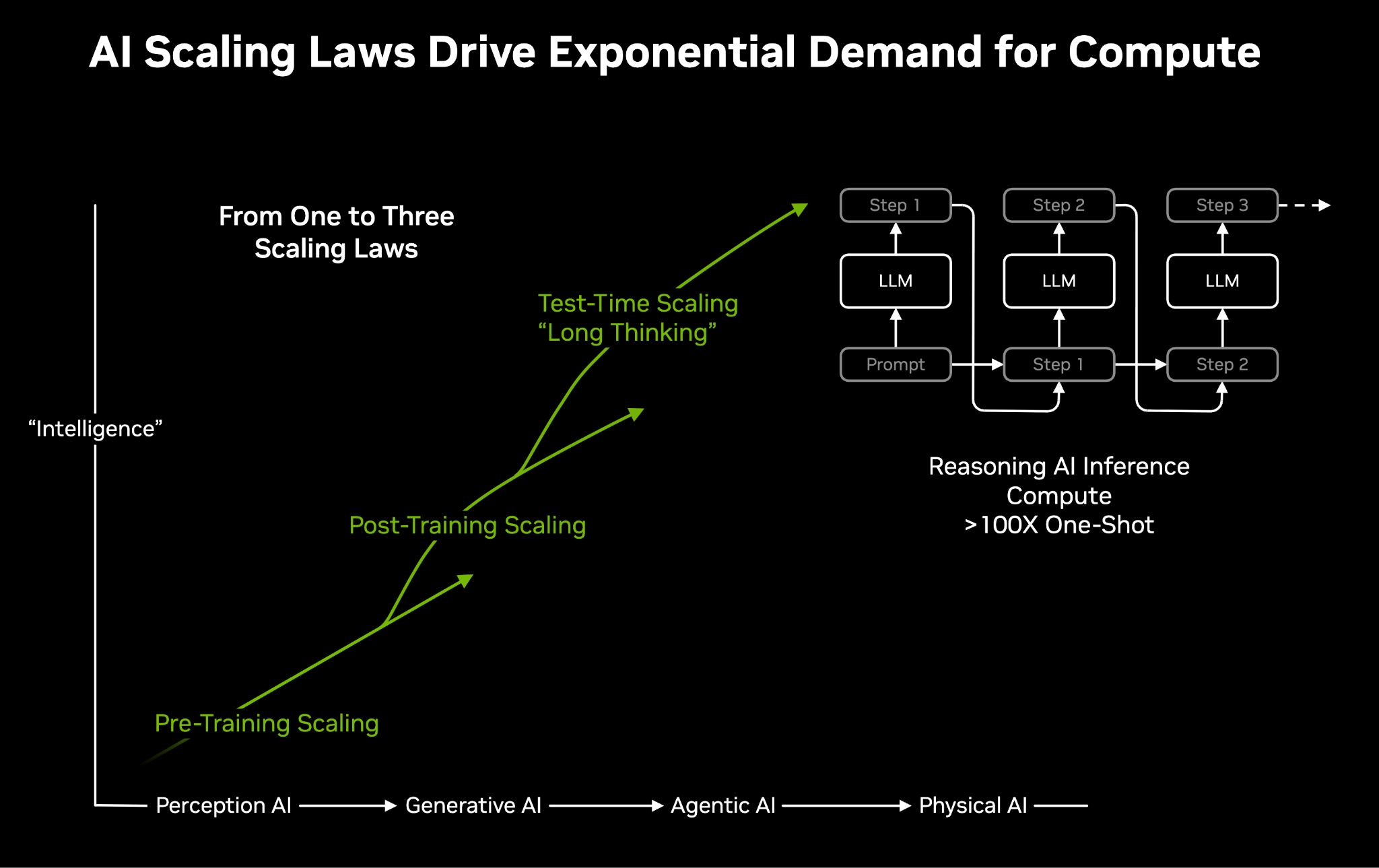
It’s this third law that resets the math. As Huang put it on BG2 recently:
“I underestimated. Let me just go on record. The old way of doing inference was one-shot. The new way is thinking. The longer you think, the better the quality answer you get. Inference isn’t going to 100× or 1,000× — it’s going to a million×, a billion×.” - Jensen Huang
But here’s the open question: do the returns justify the cost? On this week’s episode of Invest Like The Best, Dylan Patel referred to this as the log-log problem. Moving up one tier of capability can require 10× more compute for what may look like incremental gains. He likens it to going from a model that reasons like a “six-year-old” to one that reasons like a “sixteen-year-old” — transformative in practice, but punishing on the cost curve.
That tension is what everyone is watching. Can inference continue to scale linearly with investment, or do diminishing returns set in? Can efficiency gains and algorithmic breakthroughs offset the rising cost of “thinking”?
There’s also a hardware debate. GPUs currently dominate inference, but some argue that it can be done more cheaply or efficiently with ASICs or TPUs. Huang’s rebuttal is that Nvidia sells more than chips. It sells entire AI factories, co-designed across hardware, networking, and software, and system-level performance per watt matters more than the price of any single accelerator.
Inference is Nvidia’s greatest opportunity and its most scrutinized risk.
Efficiency and the Drivers
Reconciling exponential demand with finite resources requires efficiency. Nvidia’s case is that it has delivered exactly that:
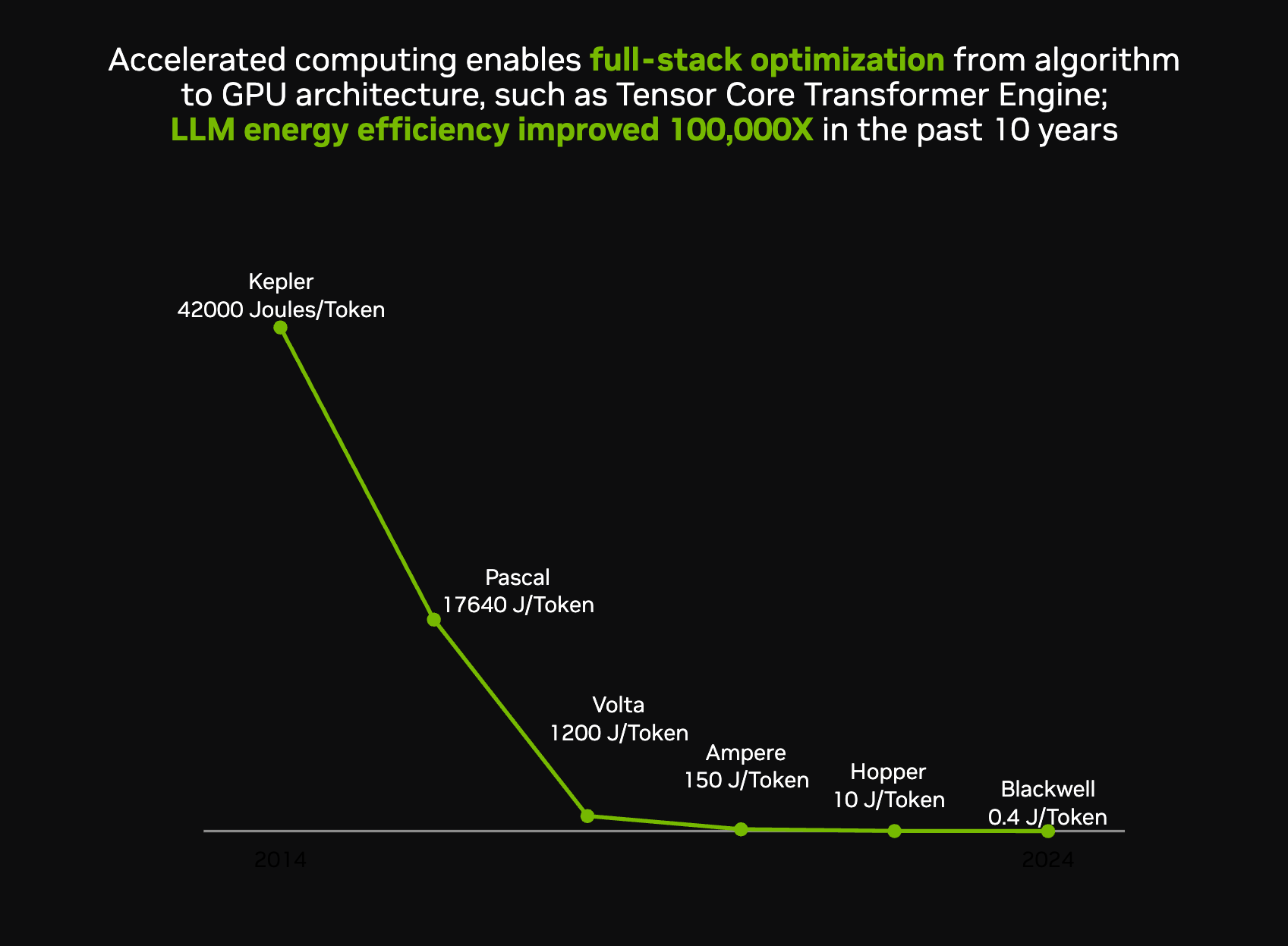
From Kepler in 2012 to Blackwell in 2025, the energy per token has decreased by ~100,000 times. Jensen attributes it to extreme co-design, where chips, networking, compilers, and systems are optimized together. Moore’s Law may be fading, but system-level innovation has kept the cost per token dropping, even as the number of tokens per task explodes.
Still, efficiency alone cannot meet demand. AI factories depend on three physical inputs: chips, data centers, and power.
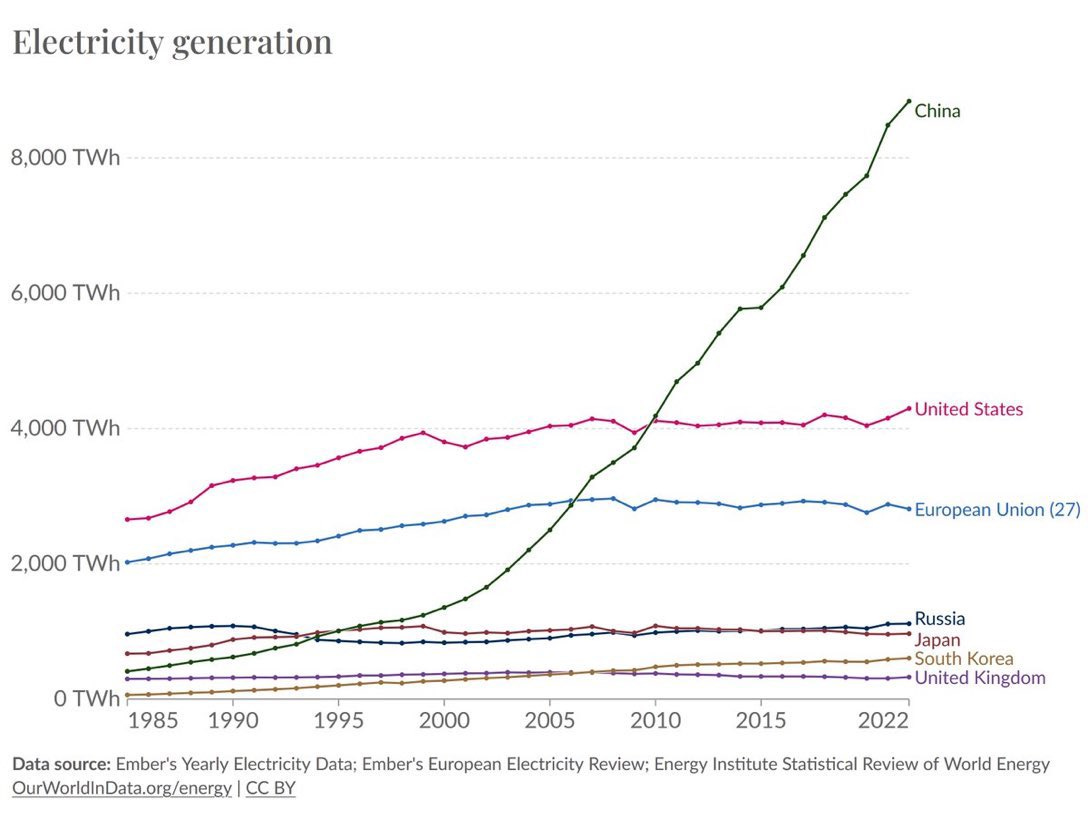
And the bottleneck is power. Huang’s analogy:
“We correlate to power. Watt is basically revenues in this future.”
Inference scaling means factories run continuously, and revenue is directly proportional to the watts consumed. This is exactly why many people point to this chart as a concern for the US.
The other constraint is financing. The combined cash flows of hyperscalers will fall short of the multi-trillion-dollar CapEx required through 2028. The balance will need to be funded through corporate debt, private credit, securitizations, and sovereign funds.
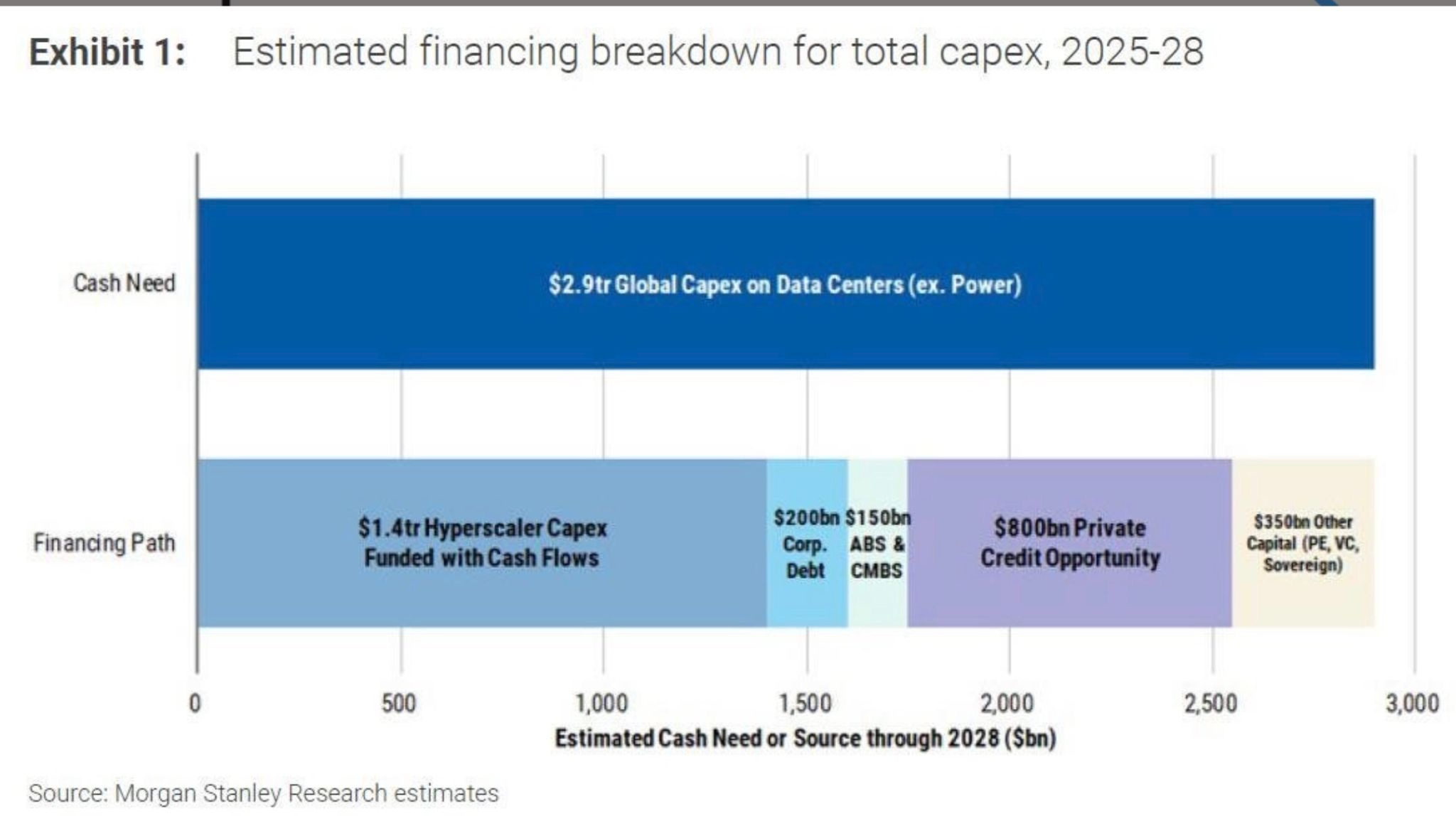
The implication is that the economics of AI are now tied to the cost of capital, the speed of grid expansion, and the appetite of global markets to finance what amounts to a new industrial revolution.
The bottom line
The central question is: how much growth will this new AI industrial revolution usher in? And when? And what kind of productivity gain will we experience? This is the biggest unknown.
Every time a technological revolution like this has occurred, whether it be the printing press, steam, electrification, PCs, or the modern internet, it has started with disruption, led to reinvention, and ultimately resulted in exponential economic expansion, growth, and abundance.
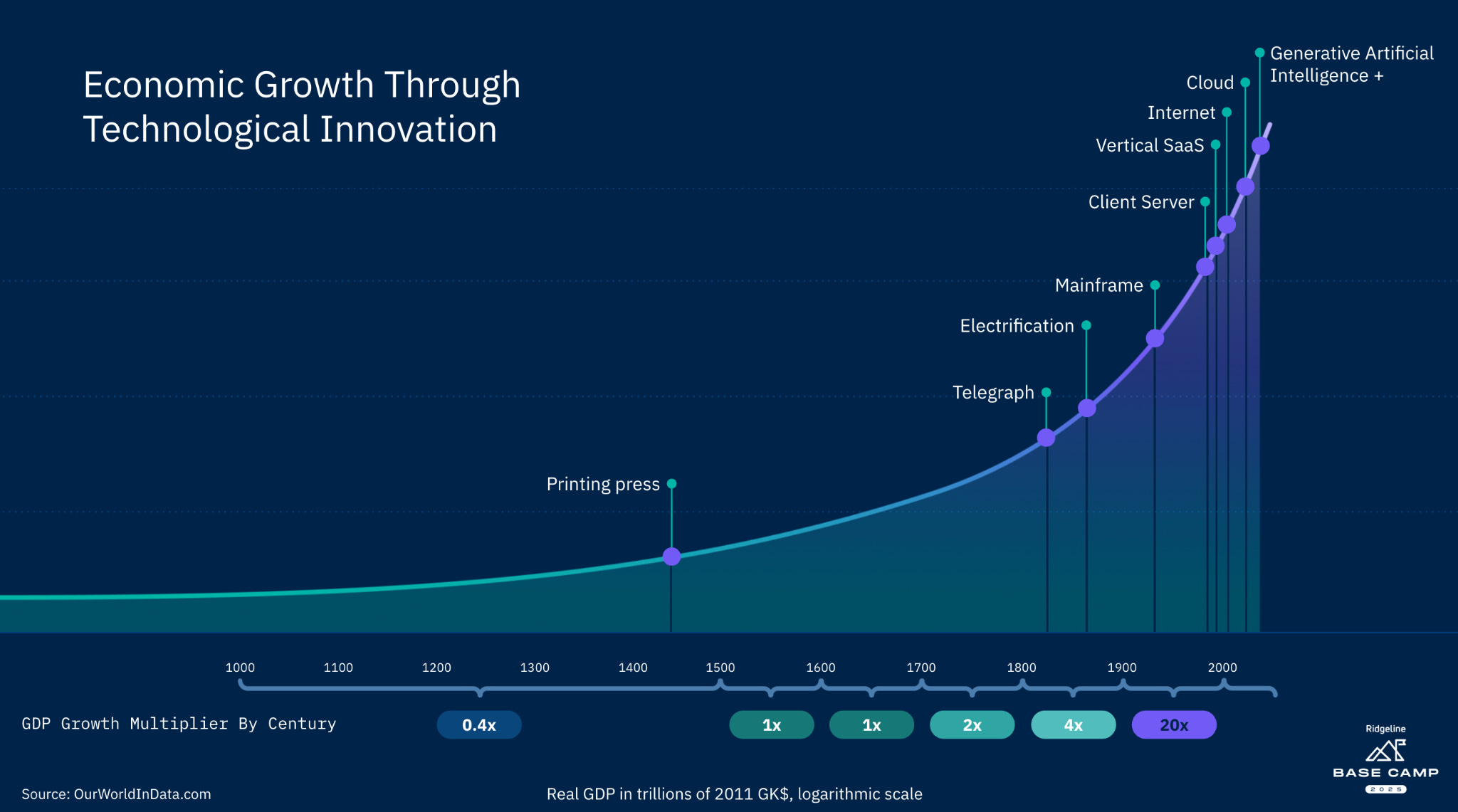
So, how fast will that economic growth arrive? There is a bull case to be made that Nvidia is on its way to a $10 trillion market capitalization. And a bear case, that spending is outpacing AI’s ability to scale, and these valuations are stretched beyond what the system can sustain.
That is why it matters to watch the right AI fundamentals driving this:
Tokens served — Is demand still compounding as reasoning and agent systems roll out? (Patel cites it’s currently doubling every 5 months)
Performance per watt — Are efficiency gains (i.e. algorithms) keeping cost-per-token falling fast enough to offset more inference?
Watts provisioned — How quickly can new gigawatts be added to the grid, and where?
CapEx posture — Do hyperscalers continue to spend at historic levels, or pause?
Financing mix — With cash flows insufficient, which capital pools step in, and at what cost?
These are just some of the inputs that will help answer the multi-trillion-dollar question: Is Nvidia still just a chip company, or are they now building AI factories capable of augmenting the intelligence of 55–65% of the world’s knowledge workers?

Best of the rest:
📱 Apple Builds a ChatGPT-Like App to Help Test the Revamped Siri – Apple is using an internal chatbot, Veritas, to trial a redesigned Siri that can search personal data and perform in-app actions, with a March 2026 launch set to decide whether the company reclaims ground in the AI race. – Bloomberg
🧩 The $10 Billion Enigma of Mira Murati – Backed by a record $2 billion seed at a $10 billion valuation, Mira Murati’s Thinking Machines has lured top OpenAI talent and investors despite having no product yet, a bet on her leadership and culture in an overheated AI market. – The Information
⚡ Abundant Intelligence – Sam Altman lays out OpenAI’s most ambitious vision yet: building a “gigawatt factory” to scale AI infrastructure weekly, betting that massive compute growth will unlock breakthroughs from curing cancer to universal tutoring and cement AI as a core economic driver. – Sam Altman’s Blog
🦾 OpenAI and NVIDIA Announce 10-Gigawatt Partnership – In a landmark deal, NVIDIA will invest up to $100 billion as OpenAI deploys at least 10 gigawatts of NVIDIA-powered AI datacenters starting in 2026, creating the infrastructure backbone for next-gen models and the race toward superintelligence. – OpenAI
🕯️ The Quiet Ones – Nikunj Kothari captures the unseen builders inside every company, the ones who quietly hold systems together but slip away when recognition lags, exposing how performance frameworks reward noise over true impact. – Nikunj Kothari

Charts that caught my eye:

→ Why does it matter? The “it” in AI is the dataset. Curious where ChatGPT gets the majority of its answers from?!

→ Why does it matter? OpenAI is on track to consume more energy by 2030 than the entire country of India produces in a year. 🤯

→ Why does it matter? Fascinating chart, especially as a technology revolution like the one we’re experiencing with AI tends to cause the world to re-order itself. Will the Mag 7 be the same in 2035?

→ Why does it matter? Hyperscaler spending on AI infrastructure is adding full percentage points to GDP growth.
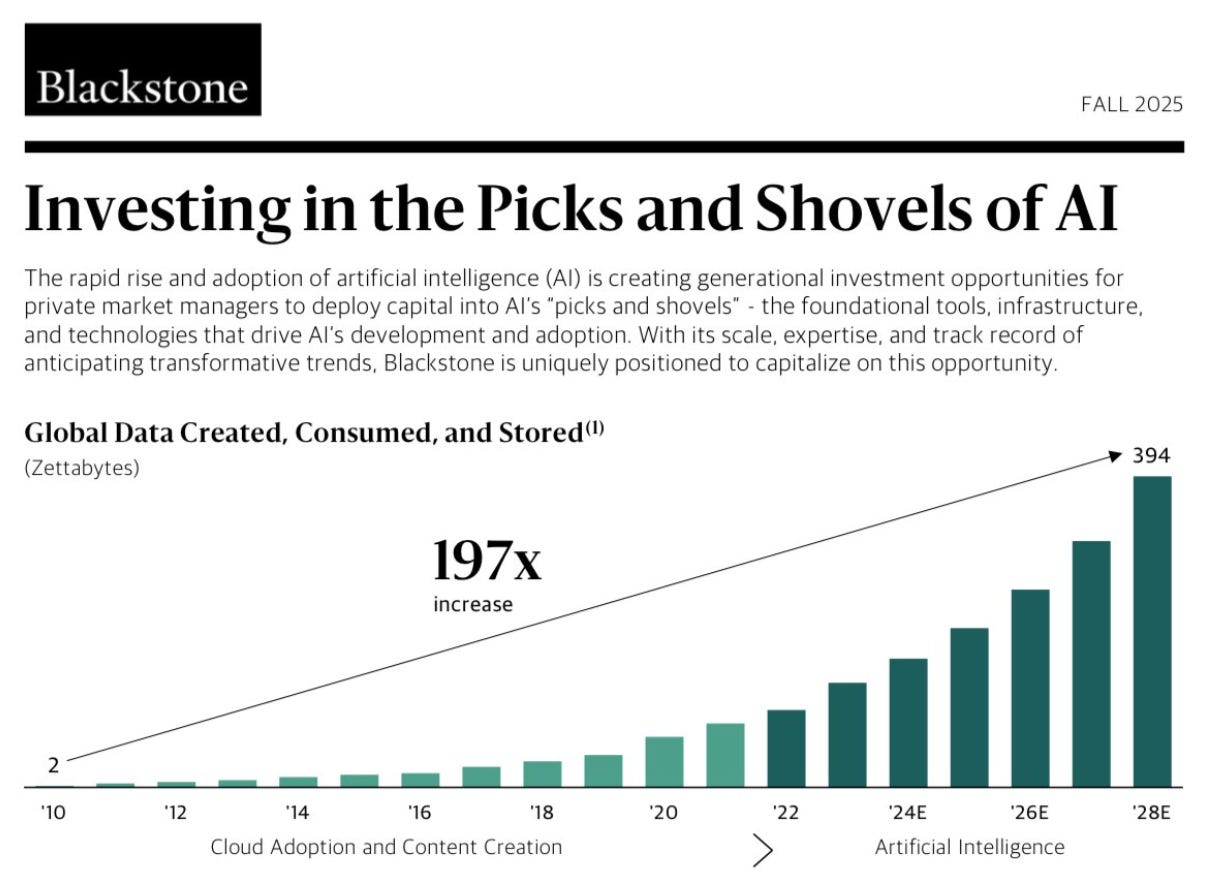
→ Why does it matter? Whoa, 394 zettabytes? That’s 394 trillion gigabytes. Enough storage for every person on Earth to stream HD movies nonstop for millions of years, or the equivalent of 394 billion laptop hard drives. At today’s internet speeds, downloading it all would take longer than the age of the universe.

Tweets that stopped my scroll:

→ Why does it matter? Honestly, this is scary, even for the ultra AI bull in me. So now OpenAI is going to launch a social media platform that is entirely AI-generated videos of ourselves and friends? Check out iJustine’s video review to see Sora in action.

→ Why does it matter? Microsoft announced that the power of AI is now available in Microsoft Excel Agent Mode. You can read more about it here. A fitting time for the “all modern digital infrastructure” hinges on an Excel file meme.

Worth a watch or listen at 1x:
→ Why does it matter? One of the best interviews with Nvidia’s CEO, Jensen Huang, I’ve ever seen.
→ Why does it matter? Marques Brownlee, one of the best tech reviewers, shows how far smart glasses have come. Recall that OpenAI recruited Jony Ive, the designer of the iPhone.

Quotes & eyewash:

→ Why does it matter? It’s funny because it’s true.

→ Why does it matter? Did you have other plans?
The mission:
The Wall Street Journal once used “Read Ambitiously” as a slogan, but I took it as a personal challenge. Our mission is to give you a point of view in a noisy, changing world. To unpack big ideas that sharpen your edge and show why they matter. To fit ambition-sized insight into your busy life and channel the zeitgeist into the stories and signals that fuel your next move. Above all, we aim to give you power, the kind that comes from having the words, insight, and legitimacy to lead with confidence. Together, we read to grow, keep learning, and refine our lens to spot the best opportunities. As Jamie Dimon says, “Great leaders are readers.”
Disclaimer: This content is for informational purposes only and does not constitute financial, investment, or legal advice. Readers should do their own research and consult with a qualified professional before making any decisions.